If you need data from websites — product prices, trending topics, job listings, social media posts, or research tables — but you do not want to write a single line of code, BrowserAct is built for you.
In this long-form guide I will walk you through exactly how BrowserAct works, the three ways to build scrapers and automations, a real-world demo using Google Trends, tips for creating reliable workflows, pricing and credit rules, integrations, and templates that speed up the process.
Here’s a detailed BrowserAct Review Video with Features Demo
What BrowserAct Does and who should use it
BrowserAct is a cloud-based, no-code web scraping and browser automation platform. It runs live browsers in the cloud to visit websites, click elements, input text, scroll pages, extract content, and produce structured outputs like CSV, JSON or XML. Because it uses an actual browser session rather than pure HTML requests, BrowserAct works on complex sites that rely on JavaScript, pagination or dynamic content.
Who benefits most from BrowserAct
- Marketers looking to extract competitor pricing, product lists or trending keywords.
- Freelancers and agencies who need quick lead lists from websites or social platforms.
- Researchers and analysts who want scheduled data pulls from news, job boards, or data portals.
- Anyone who needs to transform messy on-screen data into CSV, JSON, or XML without coding.
Three Ways to Use BrowserAct
BrowserAct offers three primary ways to build and run scraping workflows. Each path targets a different user preference — visual builders, plain-text AI agents, or programmatic integrations. I use and recommend knowing all three so you can pick the right approach depending on the task.
1. AI Workflow Builder (Visual, node-based)
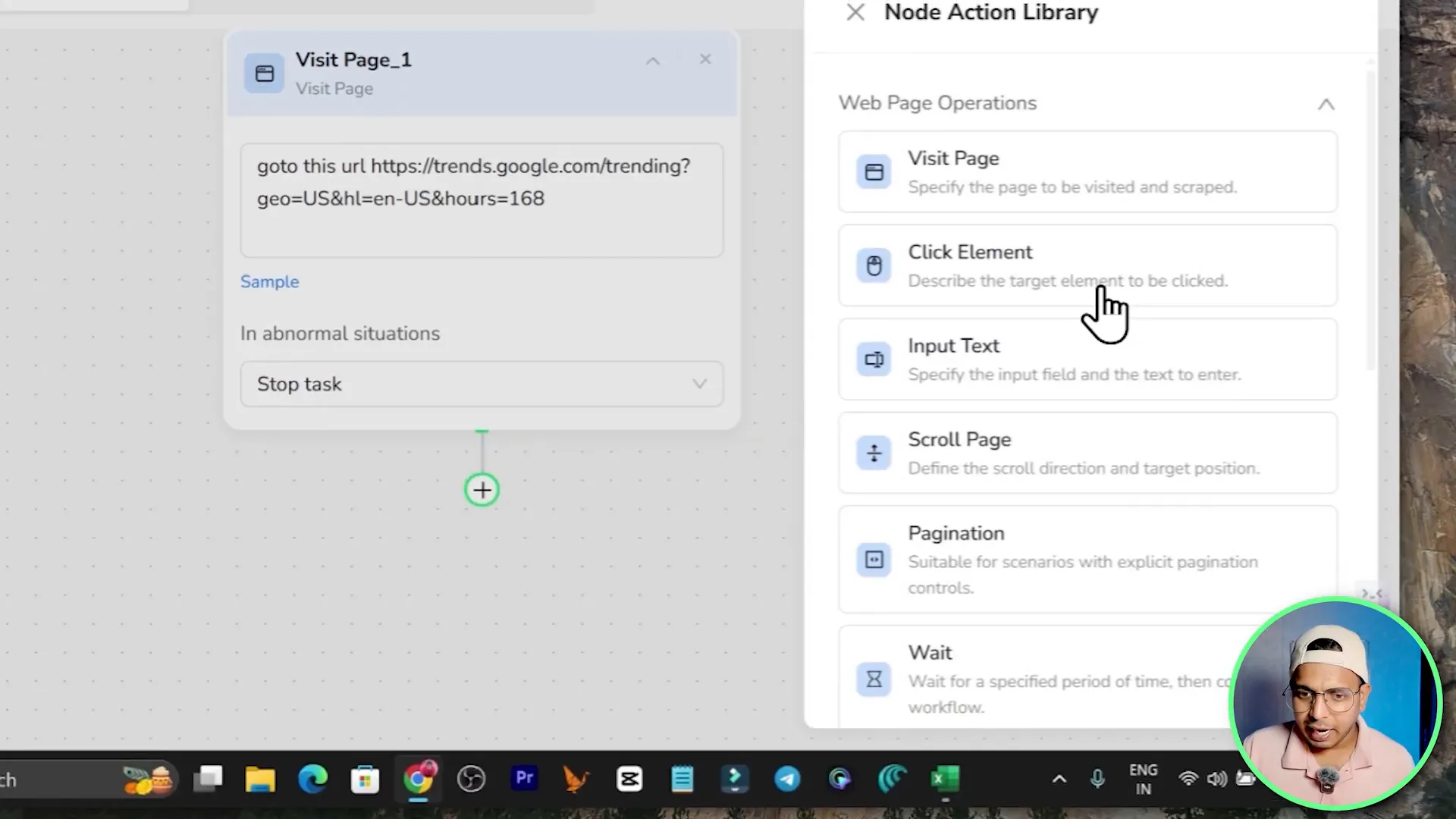
The AI workflow builder is a drag-and-drop environment where you create workflows by adding nodes. Nodes are actions like visit page, click element, input text, scroll, wait, loop, extract, and output file. If you prefer a visual flowchart approach and like to fine tune each step, this is the right place.
Key node categories
- Browser control nodes: visit page, navigate, back, refresh.
- Action nodes: click element, input text, select dropdown, scroll, wait.
- Control flow: loop, conditional branches, pagination handling.
- Extract nodes: define fields to scrape (text, links, attributes, images, table rows).
- Output nodes: save to CSV, JSON or XML; send to cloud storage or API endpoints.
Why use the AI workflow builder
- Precise control over each interaction on the page.
- Easy to debug visually when elements shift or pages load differently.
- Reusability: you can tweak and reuse nodes across workflows.
2. Quick Agent (Plain-text AI agent)
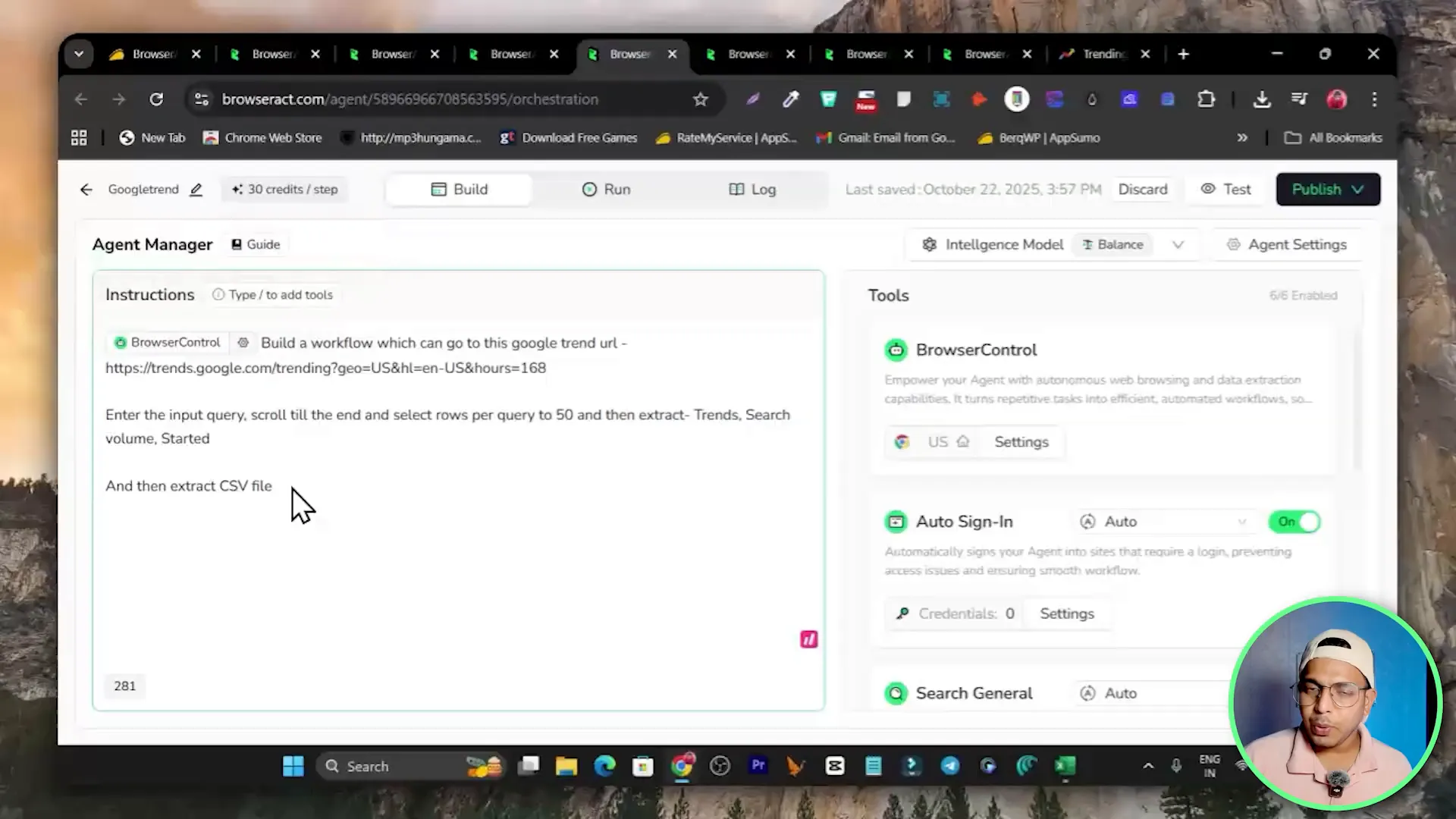
If building workflows node by node sounds tedious, BrowserAct includes a Quick Agent. This is an AI-driven agent where you explain the task in plain text and the agent builds the workflow for you. For example, you can type a sentence like:
Build a workflow that goes to this Google Trends URL, enters the input query, scrolls until the end, sets rows per page to 50, extracts trend name, search volume, start date and trend breakdown, then outputs a CSV.
The agent interprets your instructions, composes the steps, and you can then test or refine the generated workflow. It is great when you want a fast workflow without manual node-by-node design.
3. Integrations and API (Connectors)
BrowserAct can integrate with automation platforms like Make (make.com), Zapier, and tools that accept API calls. You publish a workflow and then trigger it by API from any external system, or connect the output to downstream automations.
Use cases for integrations
- Schedule daily scraping and push results into Google Sheets via Make.
- Trigger a workflow when a new lead appears and send data to your CRM through Zapier.
- Use BrowserAct as a scraping backend while processing the data in your own stack with the API response.
Step-by-step: Building a Google Trends Scraper (Complete walkthrough)
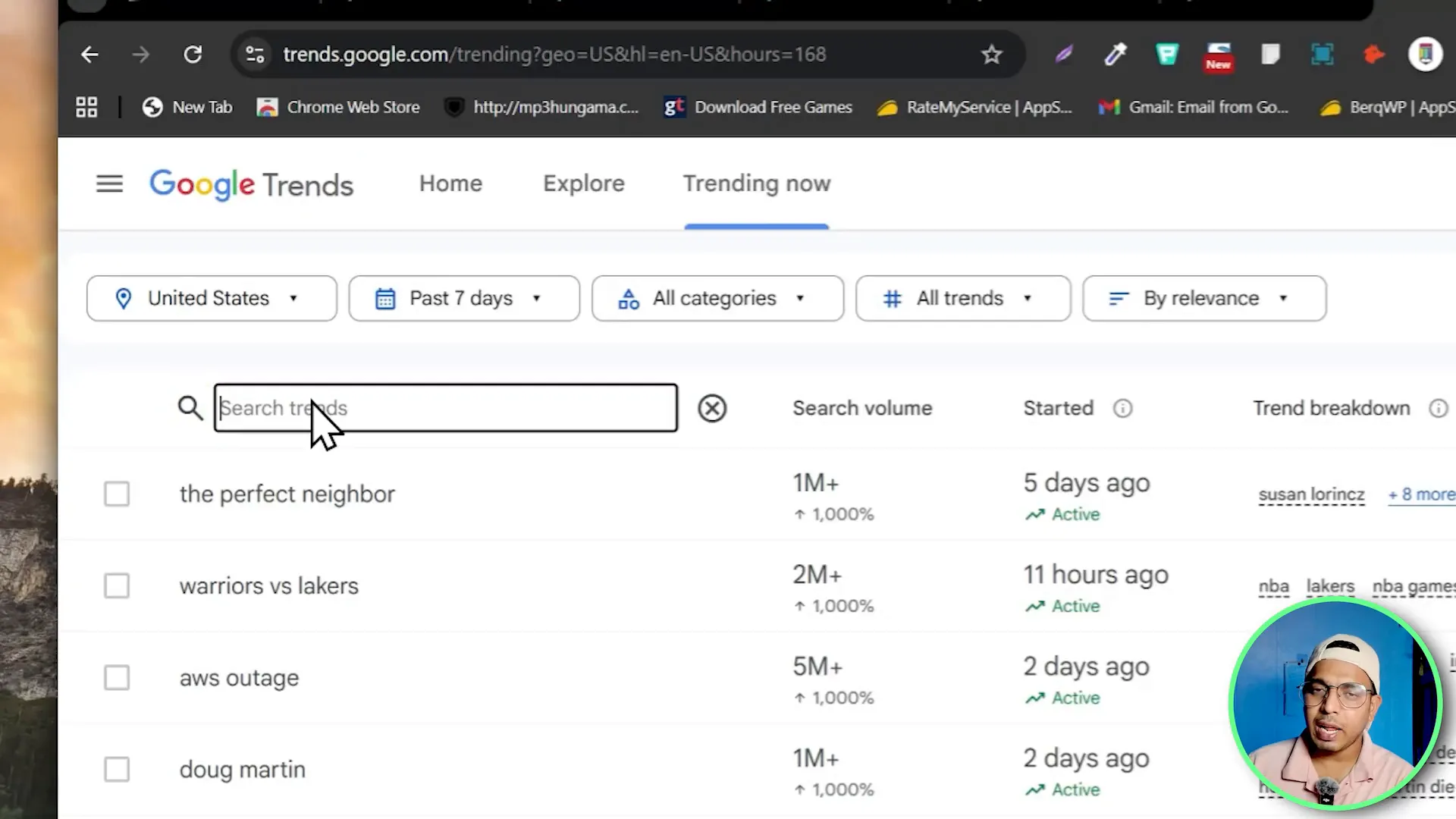
To show how BrowserAct works in practice, I built a workflow to scrape Google Trends results for a topic. This is a typical example: visit the Google Trends page, enter a search term, set rows per page to 50, scroll to load all items, extract fields and produce a CSV.
Step 1 — Create a new workflow
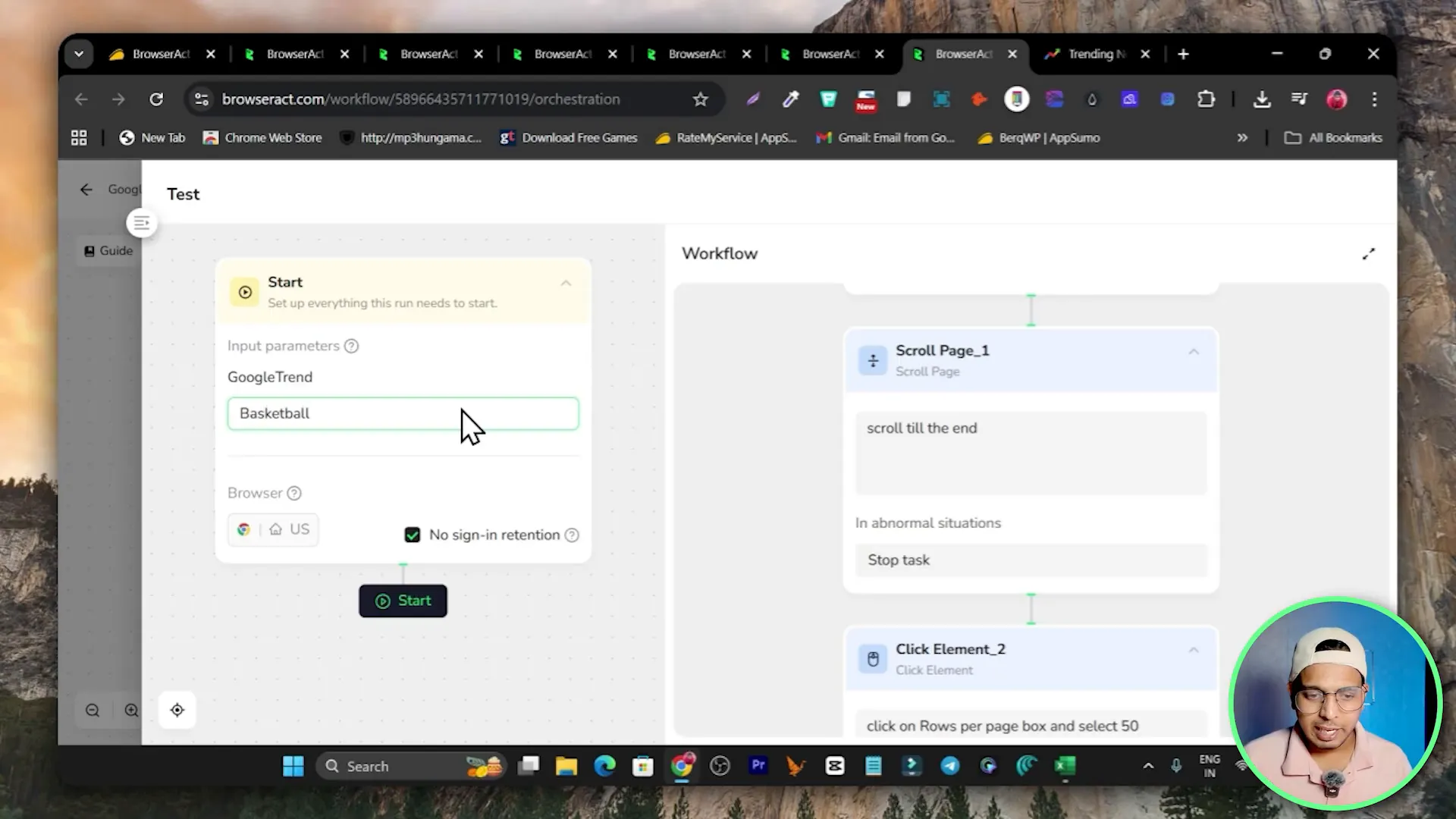
Click Create and choose the workflow option. Give your workflow a name like Google Trends Scraping and open the workflow builder. The first element is usually the input node so the workflow can accept a search keyword when you run it.
Configure an input node
- Label the input so it is clear what the user should enter (for example, Search Query or Topic).
- Decide whether the input is required or optional.
Step 2 — Visit the Google Trends URL
Add a Visit Page or Navigate node and paste the Google Trends URL. This tells the browser where to go when the workflow starts.
Step 3 — Click the search icon and input the query
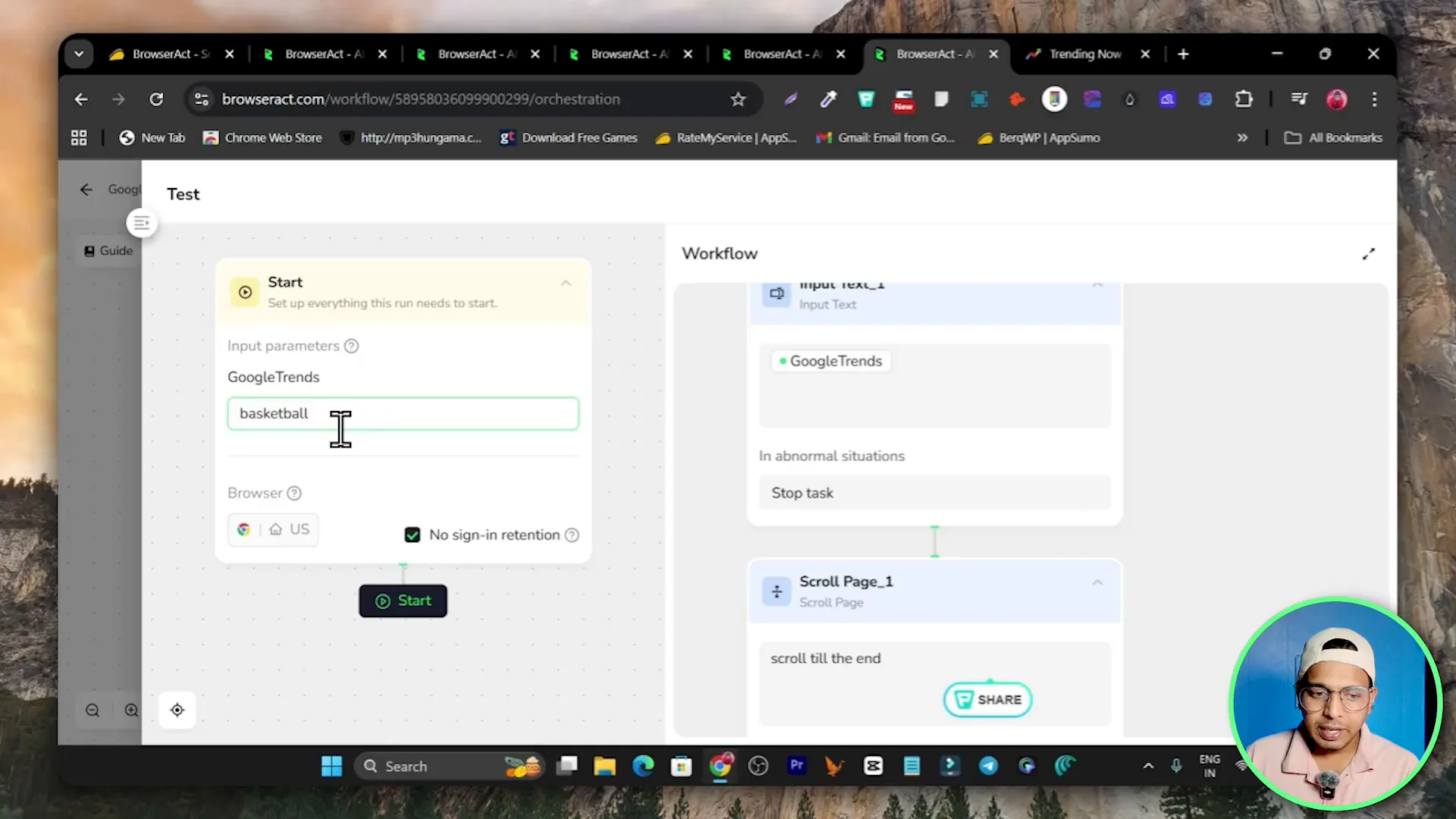
Add a Click Element node to click the search field or search icon. Then add an Input Text node to type your query into the search box. In my workflow I typed basketball as an example input during testing.
Important tip: when you click elements, select stable element selectors like button text or CSS class that are unlikely to change. If the page layout is dynamic, consider adding a brief Wait node to ensure elements have loaded before clicking.
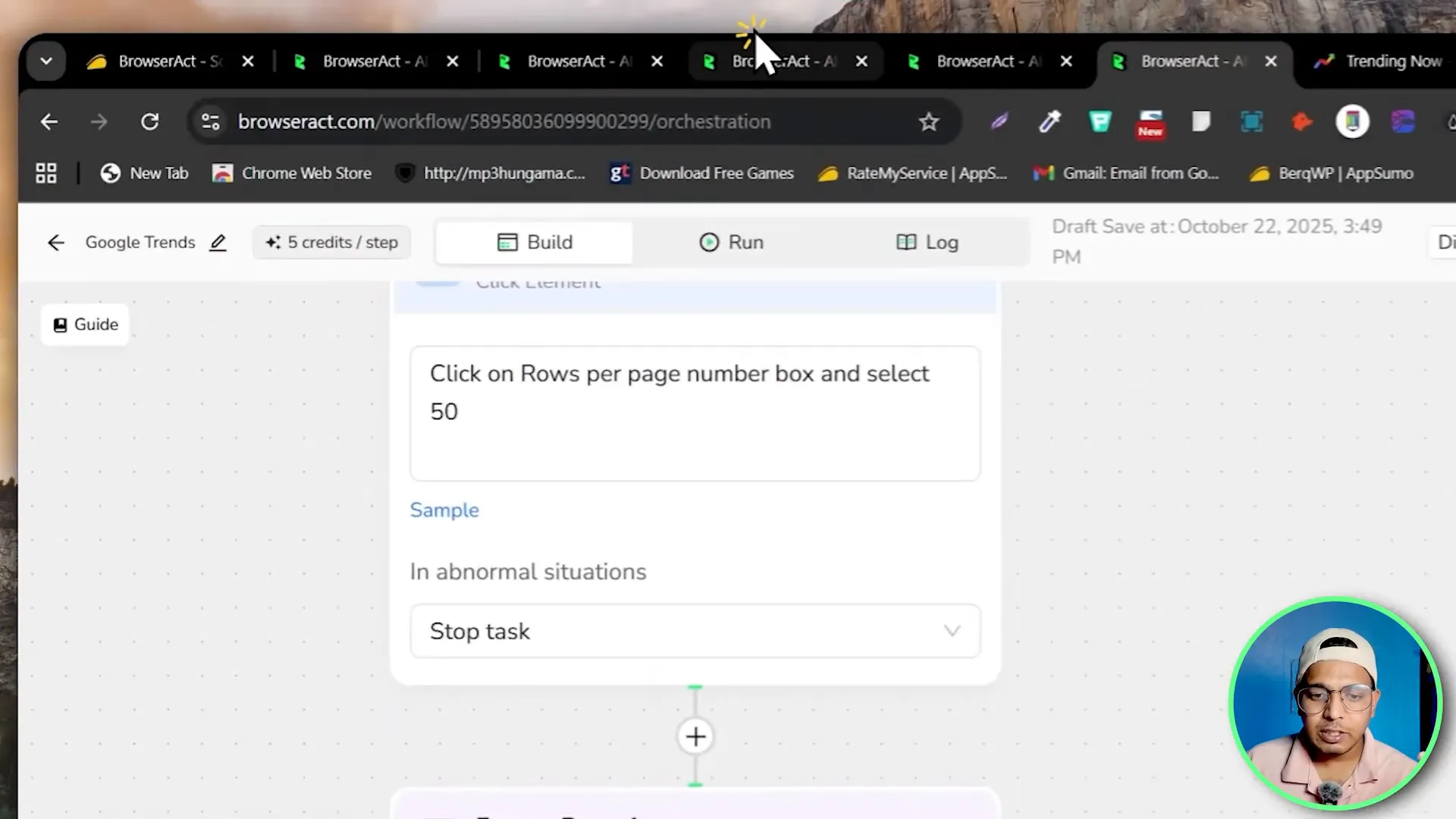
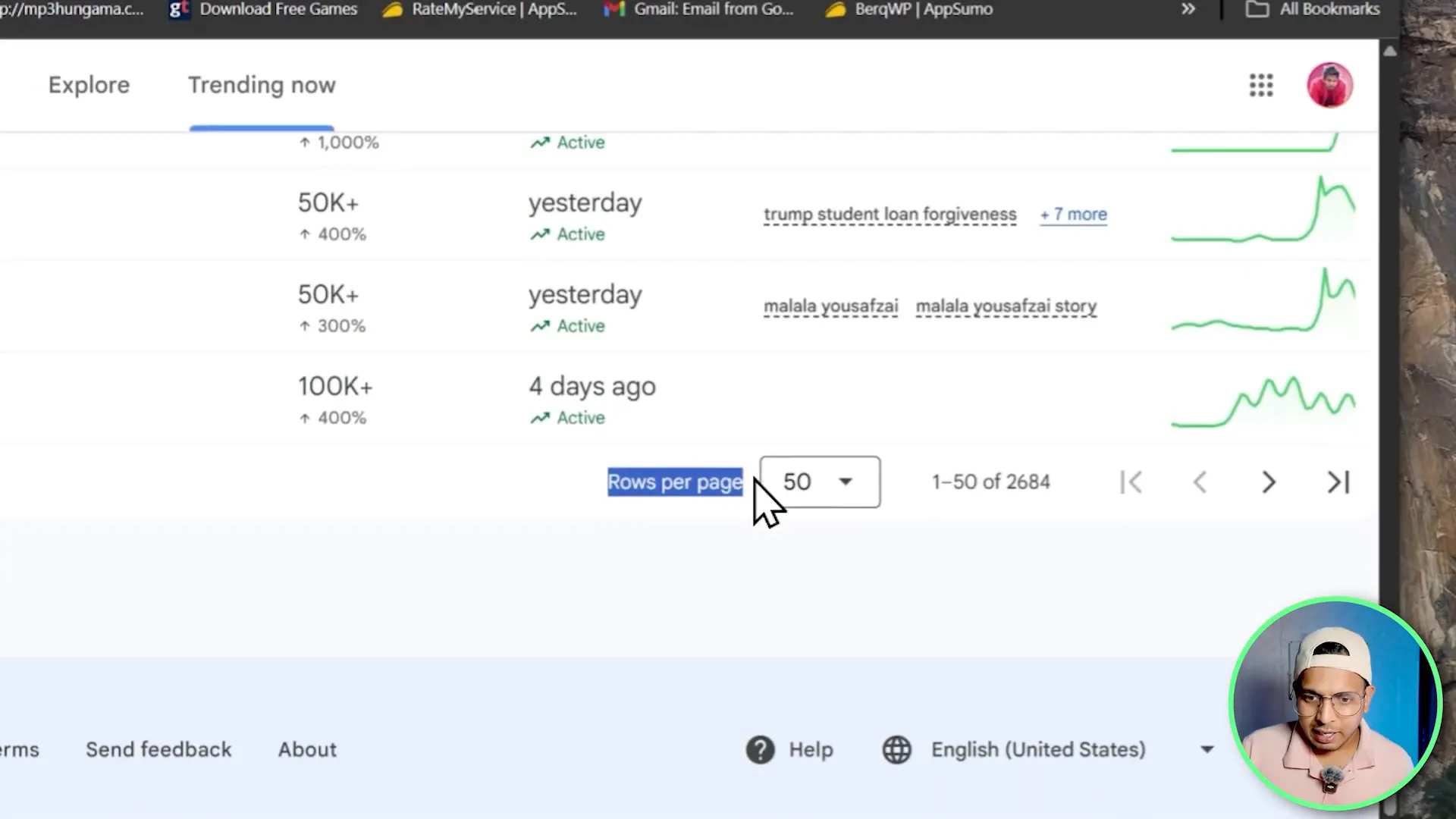
Step 4 — Pagination and scrolling
To load all results, add a Scroll node set to scroll to the end of the page. If there is a dropdown for rows per page, add a Click Element node to open the dropdown and another to select 50 rows per page. Add small Wait nodes (2–5 seconds) before and after these actions to allow the page to render.
Step 5 — Extract the data fields
Use the Extract Data node to define the data you want to capture from the page. In this Google Trends example I extracted:
- Trend name or keyword
- Search volume or relative interest
- Start date or when the trend started
- Trend breakdown or keyword breakdown
When defining extractors, use repeated selectors for list items so the extractor yields one row per trend. Preview the extracted data in the builder to ensure selectors capture the correct content.
Step 6 — Output as CSV
Add a File Output node and select CSV. BrowserAct also supports JSON and XML if you prefer hierarchical or programmatic formats. For most spreadsheet work, CSV is the easiest to consume.
Run a test
- Click Test and enter a sample query (for example basketball).
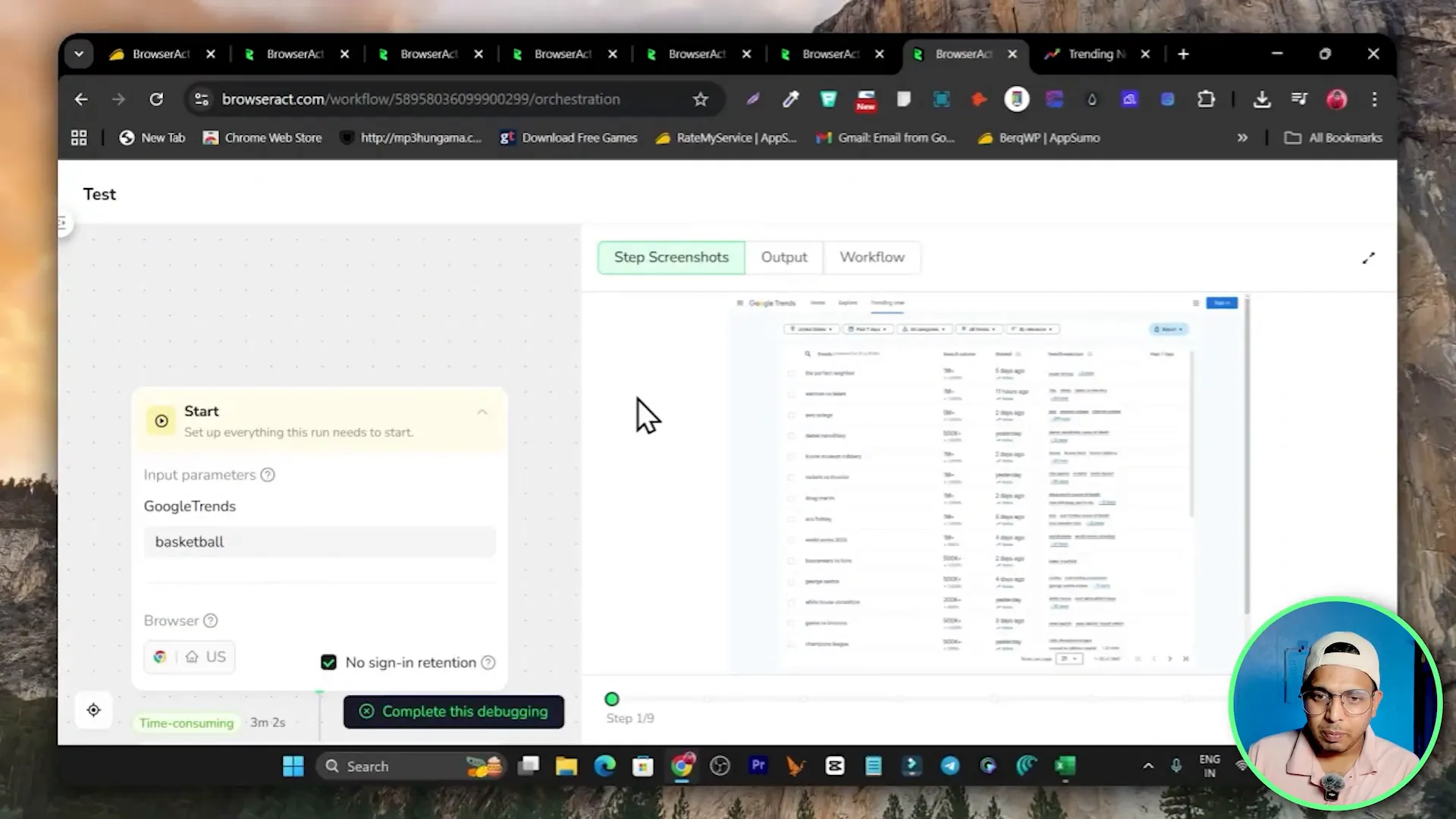
- Start the test; BrowserAct runs a live browser in the cloud and displays actions as they happen.
- Download the produced CSV to inspect the results.
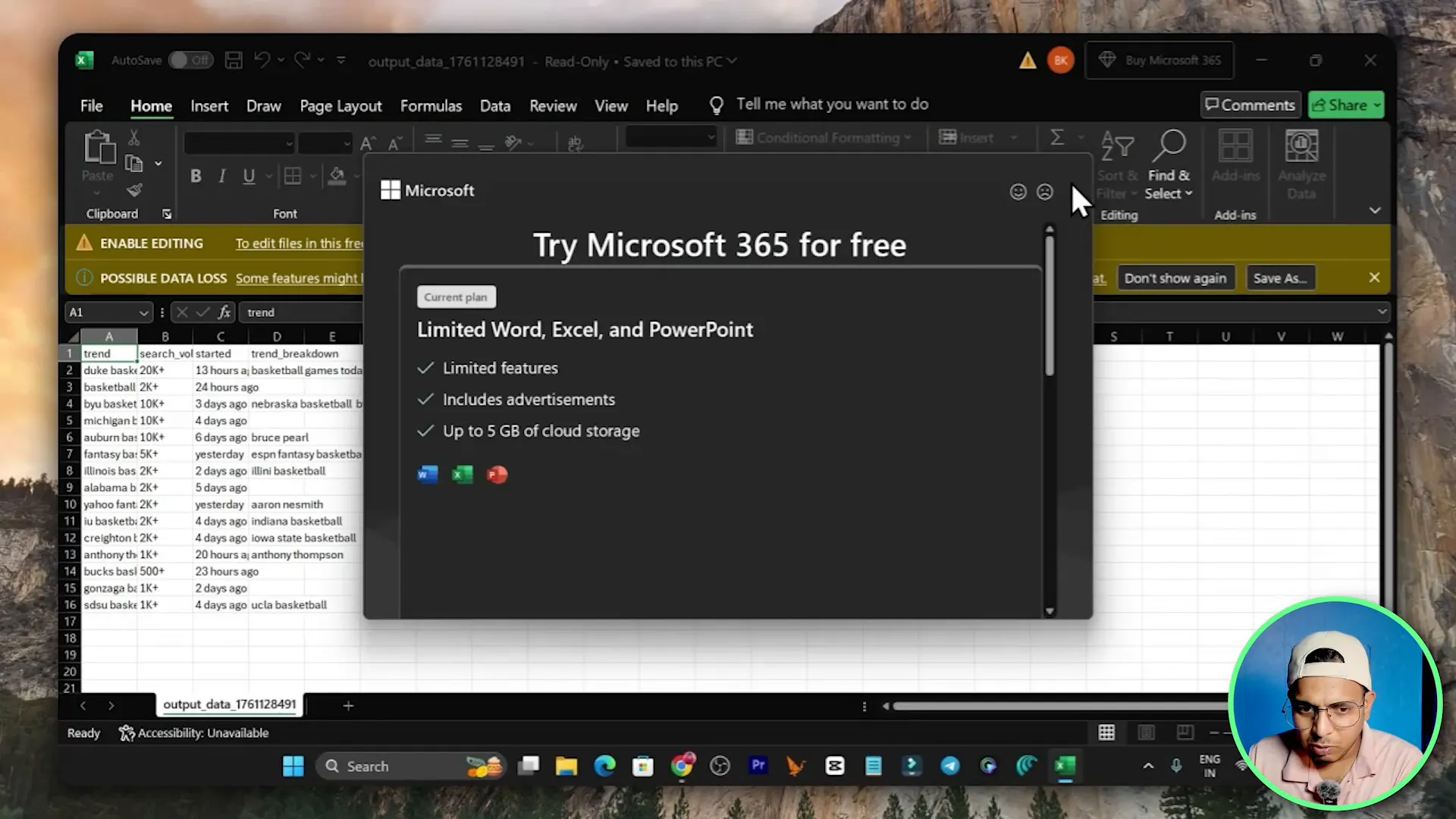
In my demo the workflow completed and produced a CSV with each basketball-related trend, its search volume and trend breakdown. If your CSV shows missing fields, revisit the extract selectors and add more precise selectors or additional waits.
Quick Agent Walkthrough — Build a workflow with plain text
If step-by-step builders are too slow, use the Quick Agent feature. You simply explain what you want the automation to do in plain English and the agent constructs the steps for you. After it generates the workflow, you can test and tweak it.
Why Quick Agent helps
- Faster to create simple scrapers without dragging nodes manually.
- Helps users who understand the process but prefer lighter, text-based setup.
- Combine Quick Agent with templates for even faster results.
Templates Marketplace — Start from a pre-built scraper
BrowserAct includes a templates marketplace with pre-built scrapers for common targets: e-commerce sites, social media platforms, news, real estate, job boards and more. Templates let you copy a workflow and customize only the selectors or inputs. If creating a workflow from scratch feels daunting, templates can save a lot of time.
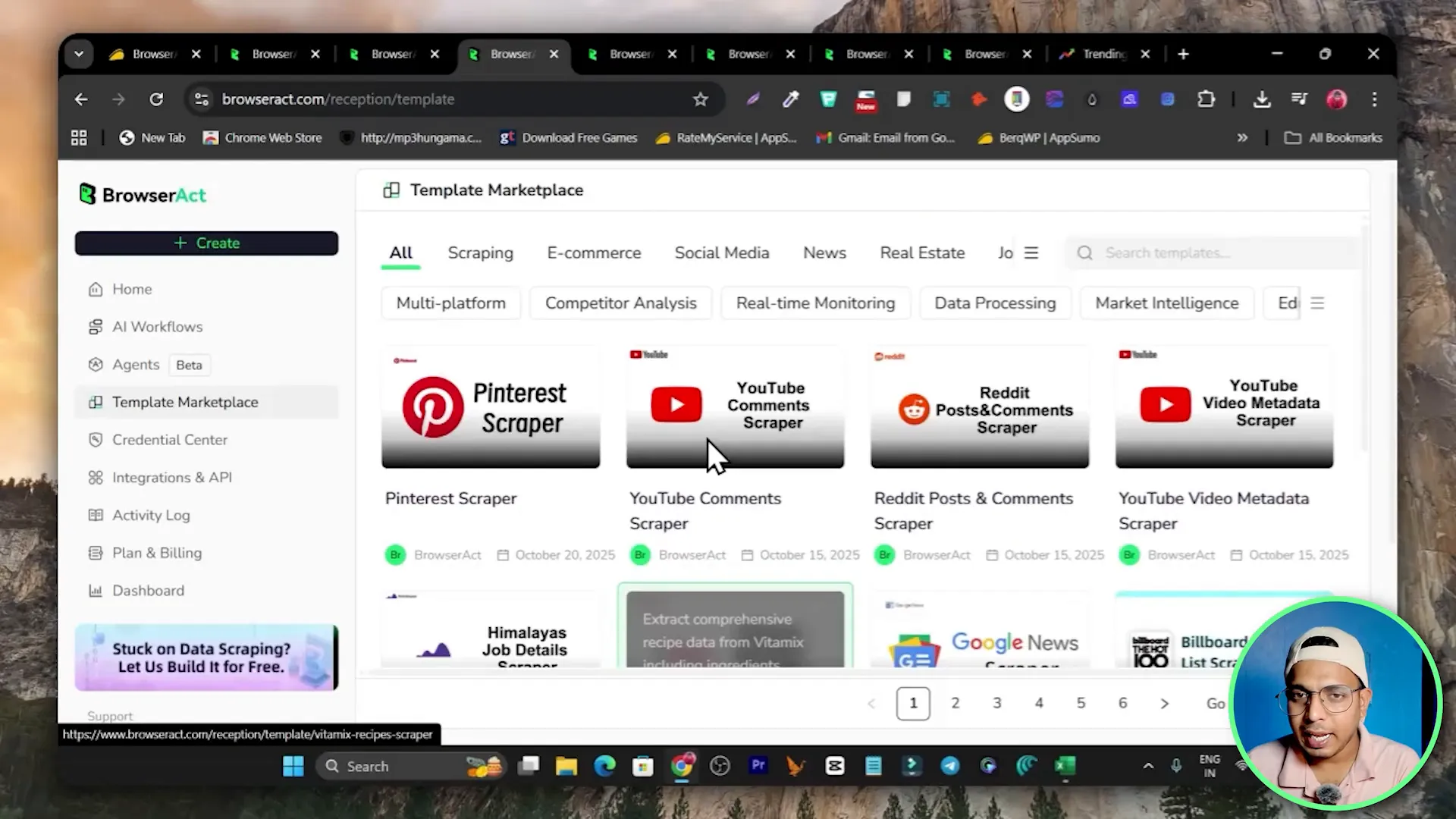
How to use templates
- Browse the template marketplace and filter by category.
- Copy a template that most closely matches your target site.
- Open the copied workflow and update any selectors or inputs specific to your target site.
- Test the workflow and adjust waits, clicks, or extraction rules as needed.
Integrations, Scheduling and Automation
Whether you want a one-off extraction or a scheduled daily scrape, BrowserAct supports automation in multiple ways. Use the built-in scheduler to run workflows at set intervals, or connect BrowserAct to Make or Zapier via API keys for advanced orchestrations.
Common automation patterns
- Schedule daily imports of product prices and push to Google Sheets or your database.
- Trigger a scrape on new leads and send results to CRM or email via Make.
- Combine BrowserAct with other APIs to enrich scraped results automatically.
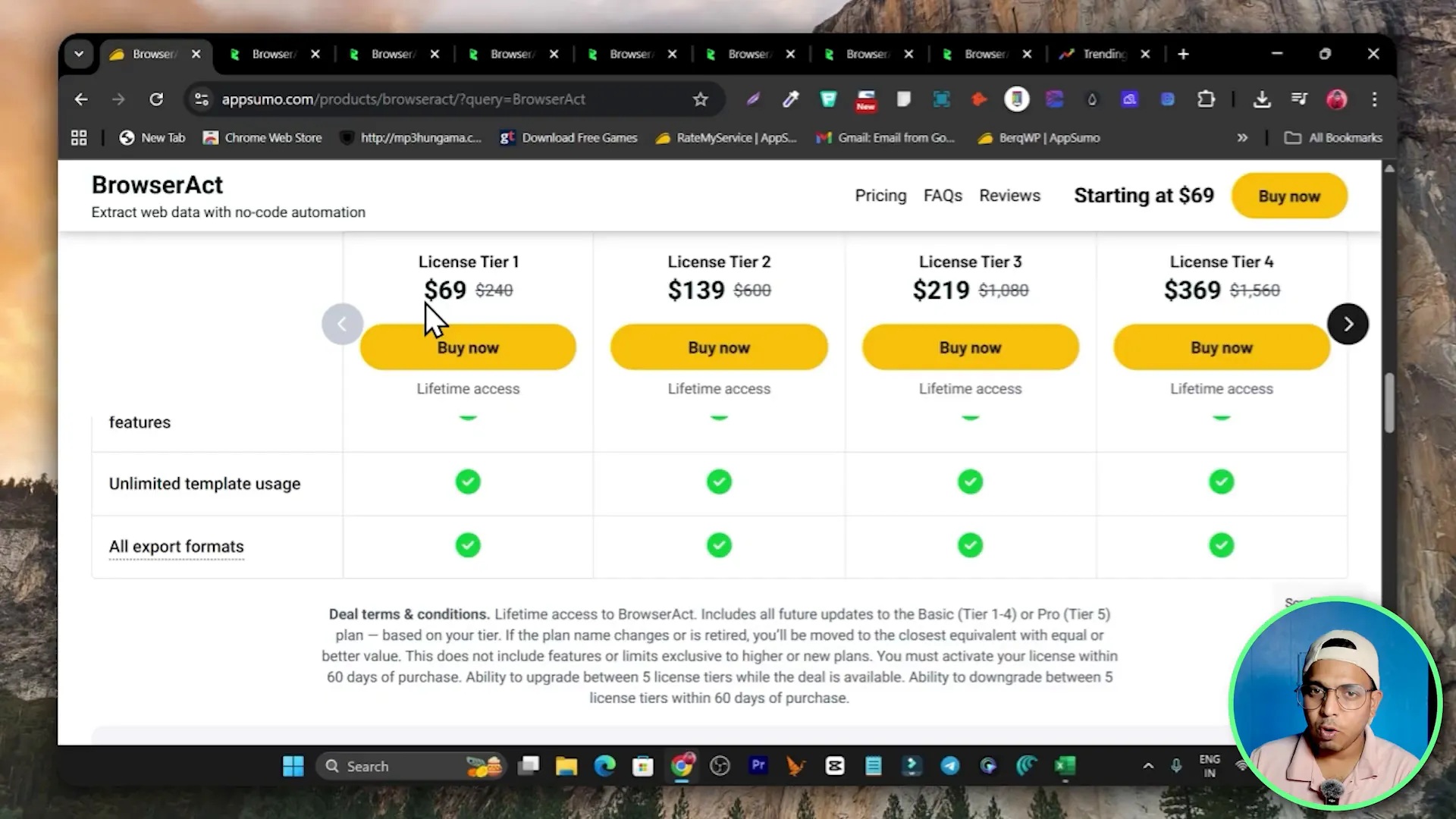
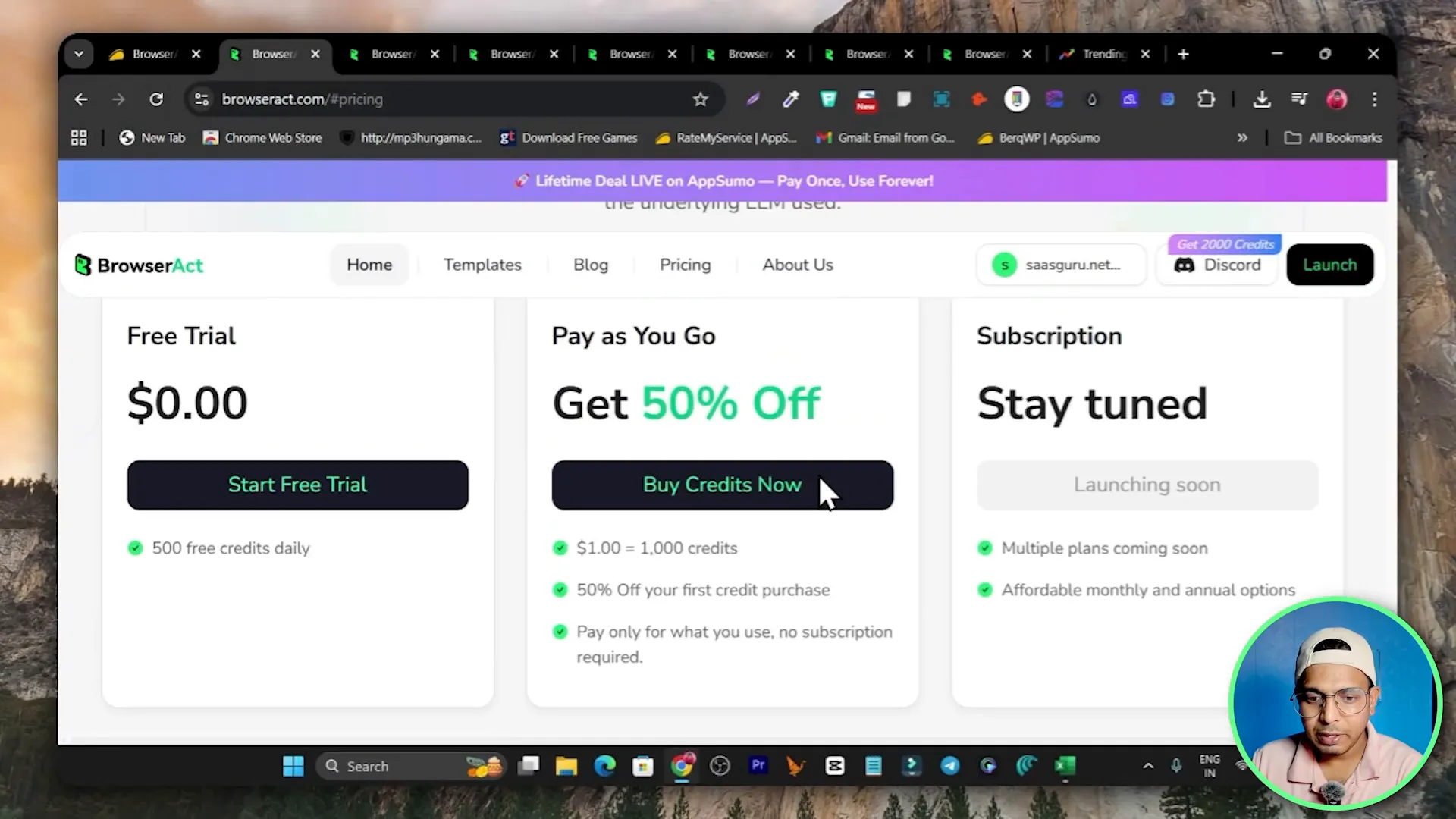
Pricing, Credits and Deals
BrowserAct uses a credits model rather than a strict monthly seat fee in some configurations. Here is how the pricing model works based on the information available:
- Credits are purchased and consumed per workflow step. Each step in your scraping process consumes credits (for example clicking, scrolling, extracting, navigation count as steps).
- The transcript example noted a rate of 5 credits per step and mentioned $1 giving a large batch of credits — confirm the current conversion within the app before buying as pricing may change.
- BrowserAct is available on AppSumo as a lifetime deal starting at one-time pricing tiers. For many users the AppSumo lifetime offer is attractive because it includes monthly credits without ongoing monthly fees.
- An example lifetime tier mentioned was $69 giving roughly 20,000 credits per month with automatic monthly renewal of credit allocation. That plan can run up to roughly 5,000 workflow steps per month which is usually sufficient for solo users and freelancers.
- Higher tiers exist for teams or heavy usage if 20,000 credits is insufficient.
Practical Tips for Reliable Scraping
Creating robust scrapers requires attention to site changes, element stability and pacing. Here are actionable tips I use to keep scrapers stable and avoid detection or failures.
- Prefer stable selectors: Use element text, data attributes, or CSS classes that are less likely to change. If classes are auto-generated, use XPath or relative selectors tied to nearby static elements.
- Add Wait nodes: Even simple sites can be slow; add 2–5 second waits after navigation and before critical clicks to ensure elements load fully.
- Use Scroll to load lazy content: For pages that load content as you scroll, use scroll actions to trigger lazy loading and then extract.
- Set Rows per page explicitly: If the site allows configuring items per page, set it to the maximum (like 50) to reduce pagination steps.
- Loop carefully: When scraping multiple pages, build loops with clear end conditions or maximum iterations to avoid infinite loops that waste credits.
- Test frequently: Run test jobs with sample inputs to confirm output structure. Download sample CSVs to validate fields and ordering.
- Monitor selectors for site updates: If a site redesigns, be ready to update extractors quickly; templates and Quick Agent outputs speed this up.
- Be mindful of terms of service: Use scraping responsibly and respect site robots rules and legal constraints.
Troubleshooting common issues
Here are problems you might encounter and how to resolve them quickly.
- Missing fields in CSV: Open the workflow, preview the page in the test environment, and re-select the correct elements for the extract node.
- Click or input failing: Add a Wait node before the click and ensure the selector targets the visible clickable element, not a hidden one.
- Infinite scrolling or missing items: Use a loop with a maximum count and verify that scroll events trigger content loading; sometimes simulating user scroll in smaller increments improves reliability.
- Authentication required: If a site needs login, use the browser control nodes to perform sign-in steps or configure credentials for secure runs.
- Credit exhaustion: Simplify workflows to reduce steps or buy higher credit packs; test with minimal runs to estimate credit use before scaling up.
Where BrowserAct fits in your tool stack
BrowserAct is a scraping and browser automation backend. Combine it with other tools for maximum leverage:
- Google Sheets or Excel for storing and analyzing CSV exports.
- Make, Zapier or n8n to orchestrate scraped data into CRMs, email lists or dashboards.
- AI writing tools to summarize scraped content or create reports (see other tools in my ecosystem).
- Use lifetime deals and curated marketplaces to reduce cost; see AppSumo lifetime offers and similar deal platforms for BrowserAct options.
Related resources on the site for deals and tools you might find useful:
- Find lifetime deals and AppSumo offerings: https://saas-guru.info
- Curated list of best AppSumo lifetime deals: https://saas-guru.info/best-appsumo-lifetime-deals/
- Best SaaS lifetime deals roundup: https://saas-guru.info/best-saas-lifetime-deals/
- AppSumo Sumo Day and special deals overview: https://saas-guru.info/appsumo-sumo-day/
- Black Friday SaaS deals and lifetime offers: https://saas-guru.info/best-black-friday-saas-deals/
Example: Real demo output and what to look for
In the demo run I started a test with basketball as the input. The live browser session executed steps: visit the Google Trends URL, click the search icon, input basketball, scroll until the end, set rows per page to 50, and extract fields. The result was a CSV showing each trend line with a search volume, start date and a trend breakdown column.
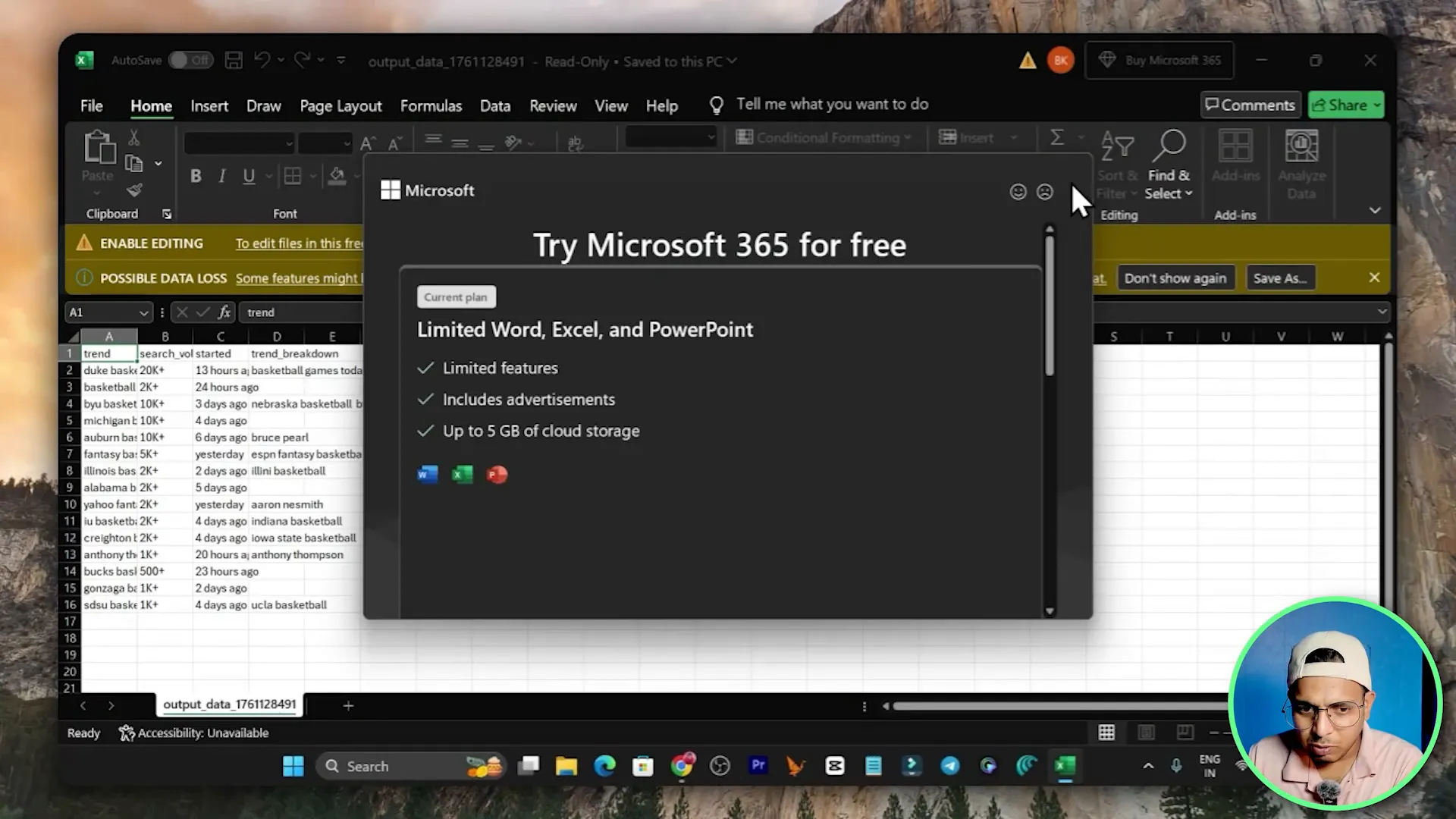
That CSV became immediately usable for research, content planning, or lead generation. If you need to enrich that CSV, connect the output to an automation platform like Make to append timestamps or run sentiment analysis via an AI API.
Pros and Cons — Quick Summary
Pros
- 100% no-code scraping and automation.
- Works on JavaScript-heavy sites because it uses live browsers.
- Multiple ways to build workflows: visual, text-based agent, or API.
- Templates dramatically speed up common scraping tasks.
- Integration with Make, Zapier and API provides powerful automation options.
- Lifetime deals on marketplaces can reduce long-term cost.
Cons
- Credits model requires monitoring consumption; steps add up.
- Browser-based scraping may be slower than raw HTTP requests but is far more reliable on modern sites.
- Some advanced sites may require login or CAPTCHA handling which needs additional setup.
Next steps — How to get started in under 10 minutes
- Create an account on BrowserAct and confirm your email.
- Decide whether you want a lifetime deal or to purchase credits.
- Open the templates marketplace and pick a template close to your target site or choose Create Workflow.
- Build the input, visit page, click/input, scroll, extract and output nodes or use the Quick Agent with a plain text instruction.
- Run a test with a single query, download the CSV and validate output. Tweak selectors if needed.
- When you are happy, publish the workflow, schedule it, or connect it to Make or Zapier using the API key for automation.
Useful links and resources
Get BrowserAct lifetime deal on AppSumo: https://appsumo.8odi.net/get_browseract
Browse additional resources and tutorials on the site:
- Find Best Saas Lifetime Deals and more: https://saas-guru.info
- Best AppSumo Lifetime Deals list: https://saas-guru.info/best-appsumo-lifetime-deals/
- Top SaaS lifetime deals and recommendations: https://saas-guru.info/best-saas-lifetime-deals/
- AppSumo Sumo Day deals and strategies: https://saas-guru.info/appsumo-sumo-day/
FAQ
What is BrowserAct and what problems does it solve?
BrowserAct is a cloud-based, no-code browser automation and web scraping tool that runs live browser sessions to navigate websites, interact with elements, and extract structured data into CSV, JSON or XML. It solves the problem of extracting data from modern, JavaScript-heavy websites without writing code, and it enables scheduling and integration with automation tools to build end-to-end data pipelines.
Do I need to code to use BrowserAct?
No. BrowserAct offers a visual AI workflow builder and a Quick Agent that accepts plain-text instructions. Both options allow you to create scrapers and automations without coding. Advanced users can also use the API for programmatic control.
How does BrowserAct handle JavaScript and dynamic content?
BrowserAct uses actual browser sessions in the cloud, so it executes JavaScript just like a real user. This lets it handle lazy loading, dynamic content, single-page apps, and other JavaScript-driven features that simple HTTP scrapers cannot parse.
How are credits consumed?
BrowserAct typically charges credits per step executed in a workflow. Actions like navigation, clicks, scrolls, extract operations and loops count as steps. The exact credit cost per step and the conversion rate for purchased credits may vary, so verify current rates in your BrowserAct account or on the AppSumo deal page.
Can BrowserAct log in to websites that require authentication?
Yes. You can build login steps into the workflow using click and input nodes to perform sign-in flows. For sites with more advanced protections or multi-factor authentication, additional setup and manual handling may be required.
What output formats does it support?
BrowserAct supports standard structured outputs such as CSV, JSON and XML. Choose CSV for spreadsheets and simple lists, JSON for nested or hierarchical data when integrating with other systems, and XML if required by downstream tools.
Can I schedule scrapers to run automatically?
Yes. BrowserAct supports scheduling workflows to run daily or at custom intervals. Alternatively, you can trigger workflows externally using the API or integrate with automation platforms like Make and Zapier to run jobs on events.
Are there pre-built templates for common scraping tasks?
Yes. BrowserAct includes a marketplace of templates for e-commerce, social media, news, real estate, jobs and more. Templates can be copied and customized so you do not have to build common scrapers from scratch.
Where can I find deals or a lifetime plan for BrowserAct?
BrowserAct appears on deal marketplaces such as AppSumo where you can sometimes purchase a lifetime plan with monthly credit allocations. Example deal link: https://appsumo.8odi.net/get_browseract. Check the deal page for current pricing and credit allocations.
What should I do if a scraper stops working?
Check for site changes first. Update extractors and selectors to match the new page structure, add Wait nodes if the page loads slower, and validate click targets. If the site introduced more protections, consider adding authentication or reducing request frequency. Test small runs to identify the failing step.
Final thoughts
BrowserAct is a powerful no-code solution for web scraping and browser automation. It provides flexibility for both beginners and advanced users: a visual builder for hands-on control, a Quick Agent for rapid text-based creation, templates for one-click starts and integrations for real automation. The cloud-based live browser approach makes it suitable for scraping modern sites that depend heavily on JavaScript.
If you are regularly extracting market data, leads, product information, or trend analysis, BrowserAct can save many hours compared to manual copying and pasting. For individual users, AppSumo or lifetime deals can be a cost-effective way to acquire credits and run hundreds or thousands of steps per month without paying ongoing subscription fees.
Start by trying a template for your target site or using the Quick Agent to describe the steps in plain English. Run a small test, inspect the CSV, and iterate on selectors. Once stable, publish and schedule the workflow or connect it to your automation stack. The combination of no-code ease and cloud execution makes BrowserAct a practical scraping tool for marketers, researchers, and agencies.